Quali sono le differenze tra un database relazionale come MySQL e un database non relazionale o NoSQL? Quale è meglio tra l’uno e l’altro?
Quando si pianifica un nuovo progetto o una nuova applicazione, spesso si discute dei requisiti del database. Che tipo di database si dovrebbe usare?
In un mondo in cui i dati sono sempre più al centro delle decisioni aziendali, è fondamentale comprendere le differenze tra i database relazionali e non-relazionali.
In questo articolo, rispondiamo a tutte queste domande ed esploriamo i concetti chiave che definiscono questi due tipi di database, spiegando cosa sono e come si differenziano i Database Relazionali vs Non-Relazionali: SQL vs NoSQL, quali i vantaggi e gli svantaggi.
Tipi di Dati
Una breve premessa sui dati nell’era digitale, che possono essere classificati in dati operativi e analitici.
I dati operativi sono utilizzati per le transazioni quotidiane e devono essere sempre aggiornati, ad esempio l’inventario dei prodotti o il saldo bancario. Questi dati vengono acquisiti in tempo reale con sistemi di elaborazione delle transazioni online (OLTP).
I dati analitici sono quelli che le aziende usano per ottenere informazioni sul comportamento dei clienti, sulle prestazioni dei prodotti e sulle previsioni. Comprendono i dati raccolti in un periodo di tempo e sono solitamente archiviati in sistemi OLAP (Online Analytical Processing), warehouse o data lake.
I database sono il modo più efficiente per archiviare e recuperare in modo permanente e digitale i dati operativi e analitici.
In base ai requisiti del progetto, le aziende devono scegliere un database in grado di raccogliere e memorizzare tutti i tipi di dati; accedervi rapidamente e ottenerne rapidi insight per prendere decisioni strategiche.
La maggior parte delle aziende ha bisogno sia dei sistemi OLTP (operativi) sia di quelli analitici (OLAP), per archiviare i propri dati, e può quindi utilizzare un database relazionale, un database non relazionale o entrambi.
Vediamoli nel dettaglio.
Cos’è un Database Relazionale (o SQL)
Un database relazionale, o sistema di gestione di database relazionali (RDMS), è basato sul modello relazionale, in cui i dati sono organizzati in tabelle con righe e colonne.
Le tabelle sono collegate tra loro tramite relazioni definite tra le chiavi primarie e le chiavi esterne. Il database relazionale utilizza il linguaggio SQL (Structured Query Language) per interrogare e manipolare i dati.

Ancora oggi i DB relazionali vengono usati per assolvere a qualsiasi esigenza informativa, in cui i dati sono correlati tra loro e devono essere gestiti in modo sicuro e coerente, per tenere traccia degli inventari, elaborare transazioni di e-commerce, gestire enormi quantità di informazioni mission-critical sui clienti, ecc.
Come funziona il DB relazionale?
Nel database relazionale, tutti i dati sono organizzati e memorizzati in strutture fisse, dette tabelle. Infatti, i database relazionali si basano sul modello relazionale, ovvero su relazioni univoche fra i dati rappresentati nelle tabelle che contengono dati specifici e di tipo diverso.
La tabella è formata da righe e colonne: ogni riga è un record con un ID univoco chiamato ‘chiave’ e contiene il dato effettivo; mentre le colonne rappresentano gli attributi dei dati.
La colonna deve contenere valori unici (‘chiave primaria’) e può essere utilizzata in altre tabelle, se si vogliono creare relazioni tra una o più tabelle. Quando la chiave primaria di una tabella viene utilizzata in un’altra tabella, la colonna della seconda tabella viene definita ‘chiave esterna’.
Facciamo un esempio di un DB relazionale.
Esempio di tabella del database relazionale
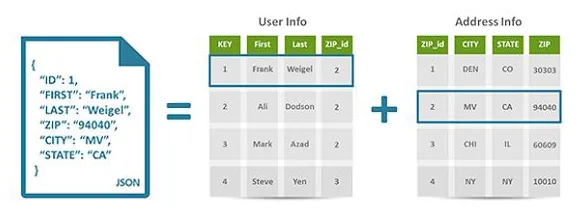
Poniamo il caso di un negozio che voglia memorizzare i nomi e gli indirizzi dei clienti in una tabella e i dettagli dei loro ordini in un’altra.
La prima tabella contiene i dati sul cliente, quindi ogni record include informazioni di contatto come il nome, l’indirizzo, i recapiti per la spedizione e la fatturazione, il numero di telefono e altre informazioni. Ogni informazione diventa un attributo contenuto in una colonna, e il database assegna un ID univoco (una chiave) a ogni riga.
Nella seconda tabella inseriamo gli ordini dei clienti, ogni record include l’ID del cliente che ha fatto l’ordine, il prodotto, la quantità, la taglia e il colore selezionati ecc., ma non il nome o le informazioni di contatto del cliente.
In sostanza, queste due tabelle condividono solo la colonna ID (la chiave), grazie alla quale il database relazionale può assolvere alla sua funzione, quindi creare una relazione tra le due tabelle per estrapolare le informazioni corrette sull’ordine del prodotto, e utilizzare l’ID del cliente da quella tabella per cercare le informazioni di fatturazione e spedizione nella tabella che contiene i dati del cliente.
Per identificare le informazioni appartenenti a uno stesso oggetto si utilizzano operazioni logiche come il JOIN, che basa i propri calcoli sulle chiavi esterne (o foreign keys), per creare il collegamento tra le due tabelle.
I vantaggi del DB relazionale
La sua “rigidità” è la faccia della medaglia buona, quella che presenta i suoi molteplici vantaggi in fatto di coerenza, sicurezza e integrità dei dati.
Per garantire che i dati siano sempre accurati e accessibili, i database relazionali seguono determinate regole di integrità. Ad esempio, una regola di integrità può specificare che non siano ammesse righe duplicate in una tabella, per eliminare le probabilità di informazioni errate nel DB.
Questo DB è la scelta consigliabile se si sta lavorando a un progetto in cui i dati sono prevedibili, in termini di struttura, dimensioni e frequenza di accesso. Non è un caso che i database relazionali si trovino spesso nelle applicazioni finanziarie.
Il modello relazionale è il migliore anche per mantenere la coerenza dei dati tra applicazioni e le copie del database (istanze). Esempio ne sia quando facciamo un’operazione offline e vogliamo però vederne gli effetti immediati nell’applicazione mobile. Le prestazioni dei database relazionali, in merito alla coerenza dei dati, sono tra le migliori permettendo a più istanze di un database di mantenere sempre gli stessi dati (coerenza).
Vediamo tutti i vantaggi del DB relazionale.
Integrità referenziale
L’integrità referenziale è una delle caratteristiche chiave dei database relazionali, garantita dalle relazioni tra le tabelle, che assicurano che i dati siano coerenti e che non si verifichino anomalie come la duplicazione o la perdita di dati.
Conformità ACID
ACID è acronimo di atomicità, consistenza, isolamento e durata, uno standard che garantisce l’affidabilità delle transazioni dei database. Il presupposto è che se una modifica fallisce, l’intera transazione fallisce, ma il database rimane nel medesimo stato in cui si trovava prima del tentativo di transazione.
Accuratezza dei dati
L’accuratezza dei dati poggia sulla esclusività delle informazioni, di cui si può evitare la duplicazione grazie alle chiavi primarie ed esterne.
Normalizzazione
Il processo di normalizzazione consiste nel garantire che i dati siano organizzati in modo da ridurre o eliminare le anomalie.
Semplicità
Anche i non addetti ai lavori possono generare report e query a partire dai dati, grazie alla longevità degli RDMS, o database SQL, e all’esistenza dei tanti strumenti e risorse per interagire con i database relazionali.
I limiti e gli svantaggi del Database Relazionale
D’altra parte, però, non possiamo ignorare i limiti di questo tipo di struttura che comporta la frammentazione delle informazioni tra differenti tabelle, anche nel caso in cui i dati descrivono lo stesso oggetto.
Per questo stesso motivo si sconsiglia l’uso di tabelle SQL troppo grandi, perché difficile da gestire anche con sistemi computazionali molto potenti.
Questa peculiarità della frammentazione richiede ai sistemi SQL di svolgere continue interrogazioni, in quanto i dati devono essere raccolti e combinati fra loro da differenti tabelle, anche per operazioni semplici (inserimento, cancellazione e aggiornamento).
Questa forte frammentazione prescrive anche un rigido controllo sulle relazioni e sulla validità dei dati inseriti nelle differenti tabelle, in modo da preservare l’integrità del database, tuttavia a scapito della flessibilità.
È anche per questo motivo che i database relazionali si basano su schemi tabellari “entità-relazione” predefiniti, che difficilmente possono essere riadattati pena il rischio di una corruzione dei dati.
Ridotte scalabilità e flessibilità
Gli RDMS nascono per essere eseguiti su un’unica macchina. Se le dimensioni dei dati non fossero supportati, ne andrebbe
migliorato l’hardware (scalabilità verticale). Questo upgrade può essere molto costoso e avere un limite massimo, oltre il quale l’hardware non può andare.
Nei database relazionali, lo schema è rigido: si definiscono le colonne e i tipi di dati per le colonne, il formato e/o la lunghezza.
Se da un lato questa caratteristica permette una maggiore facilità nell’interpretazione dei dati e nell’identificare le relazioni tra le tabelle, dall’altro è pure vero che significa che in un simile contesto operativo diventa complicato apportare modifiche alla struttura dei dati.
Ciò significa pure che quando si lavora con un DB relazionale bisogna avere le idee molto chiare fin dall’inizio su come saranno i dati. Se si volessero fare modifiche in seguito, bisogna modificare tutti i dati.
Prestazioni correlate alla complessità delle tabelle
È chiaro che maggiore è la complessità delle tabelle, in relazione al numero e alla quantità di dati contenuti in esse, maggiore è il tempo necessario per eseguire le query.
Database Non-Relazionali (NoSQL)
Cos’è un database non relazionale o NoSQL?
I database non relazionali sono completamente differenti da quelli SQL, e oggi sono diventati una necessità perché più flessibili e scalabili. Non è un caso, infatti, che siano stati progettati pensando al cloud.
Un database non relazionale può essere enorme. E poiché in alcuni casi possono crescere in modo esponenziale, hanno bisogno di un ambiente di hosting espandibile, che possa crescere con loro. La scalabilità intrinseca del cloud lo rende un ambiente ideale per i database non relazionali.
Ma andiamo per gradi.
Il database non relazionale, chiamato anche NoSQL (Not Only SQL) è un modello di database che non memorizza i dati in forma tabellare, basandosi invece su strutture di dati come i documenti. I dati sono conservati in documenti e non in tabelle.
Un documento può contenere diversi tipi di informazioni in formati diversi. Questa caratteristica rende i database non relazionali molto più flessibili di quelli relazionali, particolarmente adatti per gestire grandi volumi di dati non strutturati o semi-strutturati.
I database non relazionali memorizzano i dati in documenti, e non in strutture logiche, e vengono aggregati per oggetto in documenti di tipo Key-Value (la forma primitiva di database NoSQL) o Document Store basati su semantica JSON. Di solito, infatti, sono strutture simili a JSON che supportano una varietà di tipi di dati.
Riprendendo l’esempio di prima, in questo caso tutti i dati dei clienti vengono inseriti in un unico posto, in un solo documento.
Possono esserci diversi tipi di di DB non relazionali: database a documenti, i database a chiave-valore; i database a grafo; i database a colonne.
Quando utilizzare i DB non relazionali
I database non relazionali sono spesso utilizzati quando è necessaria la flessibilità nella memorizzazione in termini di forma o dimensione (grandi quantità di dati complessi e diversi) o se devono essere aperti ai cambiamenti futuri.
Per esempio un grande negozio potrebbe avere un database in cui ogni cliente ha un proprio documento contenente tutte le sue informazioni, dal nome e l’indirizzo allo storico degli ordini e ai dati della carta di credito. Nonostante i diversi formati, tutte queste informazioni possono essere memorizzate nello stesso documento.
I vantaggi del DB NoSQL (non relazionali)
Con l’avvento dei social, delle applicazioni mobile e del cloud computing, in un’epoca di crescente complessità dei dati provenienti da diversi fonti, nei reparti IT si è imposta la necessità di lavorare con database flessibili, scalabili, veloci.
E i database non relazionali offrono una grande flessibilità nella progettazione dei database. In particolare quando accompagnati al cloud, questi DB non relazionali eliminano i problemi relativi ai limiti della raccolta, organizzazione e analisi dei dati.
Ecco perché i database non relazionali hanno ricevuto un forte impulso di sviluppo, tanto da diventare quasi una scelta obbligata in determinati contesti, rispetto ai database relazionali o SQL.
Proprio in virtù delle diverse fonti, i dati assumono forme diverse: numeri e stringhe, contenuti fotografici e video, ecc.
In questo scenario, un database deve essere capace di memorizzare questi diversi formati di informazioni, comprendere le relazioni tra di essi ed eseguire query dettagliate.
Leggerezza computazionale
Con i database SQL, il peso computazionale cresce con l’aumento dei dati inseriti, del numero di tabelle e delle informazioni da gestire. Questo può diventare un limite, sempre considerando il contesto in cui serve disporre di un DB che risponda a determinate esigenze.
Al contrario, i database NoSQL non prevedono operazioni di aggregazione sui dati, in quanto tutte le informazioni sono già raccolte in un unico documento associato all’oggetto in questione. Il NoSQL non impone limiti di dimensioni. Infatti, i database di documenti sono adatti a gestire i “big data” e i dati non strutturati.
Assenza di schema
I database non relazionali sono schemaless, ovvero privi di tabelle e di qualsiasi schema definito a priori, in quanto il documento JSON contiene tutti i campi necessari.
In questo modo, possiamo inserire sempre nuovi dati e informazioni nei documenti JSON, senza alcuna ricaduta sulla loro integrità.
I database non relazionali, a differenza di quelli SQL, si rivelano quindi adatti a inglobare velocemente nuovi tipi di dati e a conservare dati semistrutturati o non strutturati.
Flessibilità e Scalabilità
A differenza dei database relazionali, i NoSQL non richiedono uno schema fisso, il che li rende ideali per gestire dati non strutturati o che possono cambiare nel tempo.
E ancora, a differenza dei database relazionali, per i quali è possibile scalare solo in senso verticale (CPU, spazio su disco rigido, ecc.), i database non relazionali, compresi quelli documentali, possono essere scalati in senso orizzontale. Ciò significa che i database possono distribuire i dati su più nodi per far fronte a carichi di lavoro crescenti.
Di fatto, i moderni database NoSQL sono stati progettati per il cloud, il che li rende naturalmente adatti allo scaling orizzontale grazie all’aggregazione dei dati e all’assenza di uno schema definito a priori.
Velocità
I database non relazionali non solo possono memorizzare enormi quantità di informazioni, ma possono anche interrogare questi set di dati con rapidità.
Generalmente i database non relazionali sono più veloci perché una query non deve visualizzare diverse tabelle per fornire una risposta, come invece accade con i database relazionali.
I database non relazionali sono quindi ideali per archiviare dati che possono variare spesso, o per applicazioni che gestiscono molti tipi di dati diversi. Possono supportare applicazioni in rapido sviluppo che richiedono un database dinamico, in grado di cambiare rapidamente e di ospitare grandi quantità di dati complessi e non strutturati.
Indipendentemente dal formato delle informazioni, i database non relazionali possono riunire diversi tipi di informazioni nello stesso documento.
I vantaggi di un database non relazionale risiedono nel fatto che oggi le aziende vogliono raccogliere e memorizzare quantità di dati sempre più grandi e più complessi. Dati che fanno comodo per costruire strategie di marketing sempre più precise.
Differenze tra DB SQL e DB NoSQL
A questo punto, dopo tanto scrivere, dovrebbe essere chiara la differenza principale tra i due tipi di database, che sta nella loro struttura e nel modo in cui memorizzano e gestiscono le informazioni.
I database non relazionali (NoSQL) differiscono dai database relazionali (SQL) in diversi modi, tra cui la struttura dei dati, il linguaggio di query, la scalabilità e l’affidabilità.
Ecco un recap al volo,
- Struttura dei dati: i database relazionali utilizzano il modello di dati tabellare, in cui i dati sono organizzati in tabelle composte da righe e colonne. Invece, i database NoSQL utilizzano modelli di dati flessibili e non tabellari, come per esempio i database a documenti, i database a grafo, i database a colonne e i database a chiave-valore.
- Linguaggio: il linguaggio standard per i database relazionali è il SQL (Structured Query Language), che consente di interrogare e manipolare i dati nelle tabelle.
Al contrario, i database NoSQL utilizzano spesso linguaggi di query proprietari o specifici del tipo di database, come ad esempio il MongoDB Query Language per i database documentali o il Gremlin per i database a grafo. - Scalabilità: i database relazionali sono spesso limitati nella scalabilità orizzontale, cioè nel distribuire i dati su più server per gestire grandi volumi di dati.
Al contrario, i database NoSQL sono progettati per la scalabilità orizzontale e possono gestire grandi quantità di dati in modo distribuito e scalabile. - Affidabilità: i database relazionali sono progettati per garantire una forte coerenza dei dati, il che significa che tutti i dati sono sempre disponibili e coerenti su tutti i nodi del database. Tuttavia, questa forte coerenza può influire sulla disponibilità e sulla velocità del database. I database NoSQL, invece, sono spesso progettati per garantire una maggiore disponibilità dei dati a scapito di una leggera perdita di coerenza.
Conclusioni
Cosa è meglio? Dipende.
Il database relazionale e NoSQL sono due tipi di database che utilizzano differenti modelli di dati e struttura per organizzare e gestire le informazioni.
La scelta tra database relazionali e non-relazionali dipende dalle esigenze e dalle caratteristiche specifiche del progetto.
Se è necessario lavorare con dati strutturati e garantire l’integrità referenziale, un database relazionale potrebbe essere la scelta migliore. In generale, si consideri che il database relazionale viene utilizzato per gestire grandi quantità di dati strutturati e complessi, come ad esempio i dati finanziari o i dati di inventario.
D’altra parte, se i dati sono non strutturati o cambiano frequentemente, e se la flessibilità e la scalabilità sono priorità assolute, allora un database NoSQL è la soluzione più adatta.
Con il database NoSQL, che non usa il modello tabellare, invece, possiamo gestire grandi quantità di dati non strutturati o semistrutturati, come per esempio i dati dei social media o i dati delle app mobili, delle immagini e dei sensori.
Piattaforme come Facebook, Twitter e altri social usano i database NoSQL per sfruttare la velocità di esecuzione nell’elaborazione di terabyte e terabyte di dati, la scalabilità orizzontale, un elevato livello di availability, la disponibilità di migliaia di dati non strutturati.Esiste anche la via di mezzo, ovvero l’approccio ibrido che combina database relazionali e non-relazionali, nel caso in cui si volesse trovare un equilibrio tra integrità e flessibilità dei dati.







