What are the differences between a relational database such as MySQL and a non-relational database or NoSQL? Which is better between one and the other?
When planning a new project or application, the requirements of the database are often discussed. What kind of database should be used?
In a world where data are increasingly at the centre of business decisions, it is crucial to understand the differences between relational and non-relational databases.
In this article, we answer all these questions and explore the key concepts that define these two types of databases, explaining what they are and how they differ Relational vs Non-Relational Databases: SQL vs NoSQL, what the advantages and disadvantages are.
Data Types
A brief foreword on data in the digital age, which can be classified into operational and analytical data.
Operational data are used for daily transactions and must always be up-to-date, e.g. product inventory or bank balance. This data is captured in real time with online transaction processing systems (OLTP).
Analytics data is what companies use to gain insights into customer behavior, product performance, and forecasts. They include data collected over a period of time and are usually stored in OLAP (Online Analytical Processing) systems, warehouses, or data lakes.
Databases are the most efficient way to permanently and digitally store and retrieve operational and analytical data.
Based on the project requirements, companies need to choose a database that can collect and store all kinds of data; access it quickly and get quick insights to make strategic decisions.
Most businesses need both OLTP (operational) and analytical (OLAP) systems to store their data, and can therefore use a relational database, a non-relational database, or both.
Let’s see them in detail.
What is a Relational Database (or SQL)
A relational database, or relational database management system (RDMS), is based on the relational model, where data is organized in tables with rows and columns.
Tables are linked to each other through relationships defined between primary keys and foreign keys. The relational database uses SQL (Structured Query Language) to query and manipulate data.

Relational DBs are still used today to fulfill any information need, in which data are correlated with each other and must be managed in a secure and consistent way, to keep track of inventories, process e-commerce transactions, manage huge amounts of information mission-critical on customers, etc.
How does Relational DB work?
In relational databases, all data is organized and stored in fixed structures, called tables. In fact, relational databases are based on the relational model, i.e. on unique relationships between the data represented in the tables which contain specific data of different types.
The table is made up of rows and columns: each row is a record with a unique ID called a ‘key’ and contains the actual data; while the columns represent the attributes of the data.
The column must contain unique values (‘primary key’) and can be used in other tables, if you want to create relationships between one or more tables. When the primary key of one table is used in another table, the column of the second table is called a ‘foreign key’.
Let’s take an example of a relational DB.
Example of relational database table
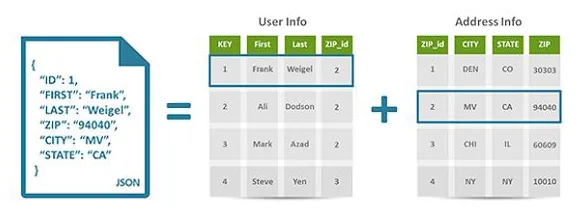
Let’s say a store wants to store customers’ names and addresses in one table and their order details in another.
The first table contains customer data, then each record includes contact information such as name, address, shipping and billing telephone and other information. Each piece of information becomes an attribute contained in a column, and the database assigns a unique ID (a key) to each row.
In the second table we enter the customer orders, each record includes the ID of the customer who placed the order, the product, quantity, size and color selected etc., but not the customer’s name or contact information.
Basically, these two tables only share the ID column (the key), thanks to this column the relational database can fulfill its function, thus creating a relationship between the two tables to pull the correct product order information, and use the customer ID from that table to look up the billing and shipping information in the table that contains the customer data.
To identify the information belonging to the same object, logical operations such as JOIN are used, which base their calculations on foreign keys, to create the link between the two tables.
The advantages of the relational DB
Its “rigidity” is the good side of the coin, the one that presents its many advantages in terms of consistency, security and data integrity.
To ensure that data is always accurate and accessible, relational databases follow certain integrity rules. For example, an integrity rule may specify that no duplicate rows are allowed in a table, to eliminate the likelihood of incorrect information in the DB.
This DB is the recommended choice if you are working on a project in which the data are predictable, in terms of structure, size and frequency of access. It is no coincidence that relational databases are often found in financial applications.
The relational model is also best for maintaining data consistency between applications and database copies (instances). An example is when we carry out an offline operation and however we want to see the immediate effects in the mobile application. The performance of relational databases, regarding data consistency, is among the best, allowing multiple instances of a database to always maintain the same data (consistency).
Let’s see all the advantages of the relational DB.
Referential integrity
Referential integrity is one of the key characteristics of relational databases, guaranteed by the relationships between tables, which ensure that the data is consistent and that no anomalies such as duplication or data loss occur.
ACID compliance
ACID stands for atomicity, consistency, isolation and duration, a standard that guarantees the reliability of database transactions. The assumption is that if a change fails, the entire transaction fails, but the database remains in the same state it was in before the transaction attempt.
Data accuracy
The accuracy of the data relies on the exclusivity of the information, the duplication of which can be avoided thanks to the primary and foreign keys.
Normalization
The normalization process consists of ensuring that data is organized in a way that reduces or eliminates anomalies.
Simplicity
Even non-experts can generate reports and queries from data, thanks to the longevity of RDMS, or SQL databases, and the existence of many tools and resources for interacting with relational databases.
The limits and disadvantages of the Relational Database
On the other hand, however, we cannot ignore the limits of this type of structure which involves the fragmentation of information between different tables, even if the data describe the same object.
For this same reason the use of too large SQL tables is not recommended, because they are difficult to manage even with very powerful computational systems.
This peculiarity of fragmentation requires SQL systems to perform continuous queries, as data must be collected and combined from different tables, even for simple operations (insertion, deletion and updating).
This strong fragmentation also prescribes strict control on the relationships and validity of the data inserted in the different tables, in order to preserve the integrity of the database, however at the expense of flexibility.
It is also for this reason that relational databases are based on predefined “entity-relationship” table schemas, which can hardly be re-adapted otherwise there is a risk of data corruption.
Reduced scalability and flexibility
RDMS are born to be run on a single machine. If the data size were not supported, the hardware would have to be
improved (vertical scalability). This upgrade can be very expensive and have an upper limit, beyond which the hardware cannot go.
In relational databases, the schema is rigid: you define the columns and the data types for the columns, the format and/or the length.
While on the one hand this feature allows for greater ease in interpreting the data and identifying the relationships between the tables, on the other it is also true that it means that in such an operational context it becomes complicated to make changes to the data structure.
This also means that when working with a relational DB you need to have very clear ideas from the outset on how the data will be. If you want to make changes later, you have to change all the data.
Performance related to table complexity
It is clear that the more complex the tables, in relation to the number and amount of data contained in them, the more time it takes to execute the queries.
Non-Relational Databases (NoSQL)
What is a non-relational or NoSQL database?
Non-relational databases are completely different from SQL databases, and today they have become a necessity because they are more flexible and scalable. It is no coincidence, in fact, that they have been designed with the cloud in mind.
A non-relational database can be huge. And because they can grow exponentially in some cases, they need an expandable hosting environment, that can grow with them. The inherent scalability of the cloud makes it an ideal environment for non-relational databases.
But let’s go step by step.
Non-relational database, also called NoSQL (Not Only SQL) is a database model that does not store data in tabular form, instead relying on data structures such as documents. The data is stored in documents and not in tables.
A document can contain different types of information in different formats. This feature makes non-relational databases much more flexible than relational ones, particularly suitable for handling large volumes of unstructured or semi-structured data.
Non-relational databases store data in documents, and not in logical structures, and are aggregated by object in Key-Value type documents (the primitive form of NoSQL database) or Document Stores based on JSON semantics . In fact, they are usually JSON-like structures that support a variety of data types.
Taking the example above, in this case all customer data is entered in one place, in one document.
There can be different types of non-relational DBs: document databases, key-value databases; graph databases; columnar databases.
When to use non-relational DBs
Non-relational databases are often used when flexibility in storage in terms of shape or size is required (large amounts of complex and diverse data) or if they need to be open to future changes.
For example, a large store could have a database in which each customer has his own document containing all of his information, from name and address to order history and credit card information. Despite the different formats, all this information can be stored in the same document.
The benefits of NoSQL (non-relational) DB
With the advent of social media, mobile applications and cloud computing, in an era of growing complexity of data from different sources, the need to work with flexible, scalable, fast databases.
And non-relational databases offer great flexibility in database design. Particularly when developed to the cloud, these non-relational DBs eliminate concerns about the limitations of data collection, organization and analysis.
This is why non-relational databases have received a strong development impetus, to the point of becoming almost an obligatory choice in certain contexts, compared to relational or SQL databases.
Precisely because of the different sources, data takes on different forms: numbers and strings, photographic and video content, etc.
In this scenario, a database must be capable of storing these different formats of information, understanding the relationships between them, and performing detailed queries.
Computational lightness
With SQL databases, the computational weight grows as the data entered, the number of tables and the information to be managed increase. This can become a limitation, always considering the context in which it is necessary to have a DB that responds to certain needs.
On the contrary, NoSQL databases do not include data aggregation operations, as all the information is already collected in a single document associated with the object in question. NoSQL does not impose size limits. In fact, document databases are well suited to handling “big data” and unstructured data.
Absence of scheme
Non-relational databases are schemaless, i.e. without tables and any schema defined a priori, as the JSON document contains all the necessary fields.
In this way, we can always insert new data and information into JSON documents, without any impact on their integrity.
Non-relational databases, unlike SQL ones, are therefore suitable for quickly incorporating new types of data and for storing semi-structured or unstructured data.
Flexibility and Scalability
Unlike relational databases, NoSQLs don’t require a fixed schema, making them ideal for dealing with unstructured data or data that can change over time.
And again, unlike relational databases, for which it is only possible to scale vertically (CPU, hard disk space, etc.), non-relational databases, including document databases, can be scaled horizontally. This means that databases can distribute data across multiple nodes to accommodate growing workloads.
In fact, modern NoSQL databases were designed for the cloud, which makes them naturally suitable for horizontal scaling thanks to data aggregation and the absence of a predefined schema.
Speed
Non-relational databases can not only store huge amounts of information, they can also query these datasets rapidly.
Non-relational databases are generally faster because a query doesn’t have to view several tables to provide an answer, as is the case with relational databases.
Non-relational databases are therefore ideal for storing data that can vary often, or for applications that handle many different types of data. They can support rapidly developing applications that require a dynamic, rapidly changing database that can accommodate large amounts of complex, unstructured data.
Regardless of the format of the information, non-relational databases can combine different types of information in the same document.
The advantages of a non-relational databasereside in the fact that companies today want to collect and store ever larger and more complex amounts of data. Data that is useful for building increasingly precise marketing strategies.
Differences between DB SQL and DB NoSQL
At this point, after much writing, the main difference between the two types of databases should be clear, which lies in their structure and the way they store and manage information.
Non-relational databases (NoSQL) differ from relational databases (SQL) in several ways, including data structure, query language, scalability and reliability.
Here is a quick recap,
- Data Structure: Relational databases use the tabular data model, where data is organized into tables made up of rows and columns. Instead, NoSQL databases use flexible, non-tabular data models, such as document databases, graph databases, columnar databases, and key-value databases.
- Language: The standard language for relational databases is SQL (Structured Query Language), which allows you to query and manipulate data in tables.
In contrast, NoSQL databases often use proprietary or database-type specific queries, such as MongoDB Query Language for document databases or Gremlin for graph databases. - Scalability: Relational databases are often limited in horizontal scalability, i.e. in distributing data across multiple servers to handle large volumes of data.
In contrast, NoSQL databases are designed to scale horizontally and can handle large amounts of data in a distributed and scalable manner. - Reliability: Relational databases are designed for strong data consistency, which means that all data is always available and consistent across all database nodes. However, this strong consistency can impact database availability and speed. NoSQL databases, on the other hand, are often designed to ensure greater data availability at the expense of a slight loss of consistency.
Conclusions
What is better? Depends.
Relational database and NoSQL are two types of databases that use different data models and structure to organize and manage information.
The choice between relational and non-relational databases depends on the specific needs and characteristics of the project.
If you need to work with structured data and ensure referential integrity, a relational database may be the best choice. In general, consider that the relational database is used to handle large amounts of structured and complex data, such as financial data or inventory data.
On the other hand, if your data is unstructured or changes frequently, and flexibility and scalability are top priorities, then a NoSQL database is your best bet.
With the NoSQL database, which does not use the tabular model, however, we can manage large amounts of unstructured or semi-structured data, such as social media data or data from mobile apps, images and sensors.
Platforms such as Facebook, Twitter and other social networks use NoSQL databases to take advantage of the speed of execution in processing terabytes and terabytes of data, horizontal scalability, a high level of availability, the availability of thousands of unstructured data. There is also the middle ground, which is the hybrid approach that combines relational and non-relational databases, in case you want to strike a balance between data integrity and flexibility.







